5.
教程中的一些术语:
Model representation:
其实就是指学习到的函数的表达形式,可以用矩阵表示。
Vectorized implementation:
指定是函数表达式的矢量实现。
Feature scaling:
指是将特征的每一维都进行一个尺度变化,比如说都让其均值为0等。
Normal equations:
这里指的是多元线性回归中参数解的矩阵形式,这个解方程称为normal equations.
Optimization objective:
指的是需要优化的目标函数,比如说logistic中loss function表达式的公式推导。或者多元线性回归中带有规则性的目标函数。
Gradient Descent、Newton’s Method:
都是求目标函数最小值的方法。
Common variations:
指的是规则项表达形式的多样性。
4.
BP网络训练开始之前,对网络的权重和偏置值进行初始化,权重取[-1,1]之间的一个随机数,偏置取[0,1]间的一个随机数。神经网络的训练包含多次的迭代过程,每一次迭代(训练)过程都使用训练集的所有样本。
每一轮训练完成后判断训练样本的分类正确率和最大训练次数是否满足设定条件,如果满足则停止训练,不满足则从前向传输进入到逆向传输阶段。
3.
上图中隐藏层只画了一层,但其层数并没有限制,传统的神经网络学习经验认为一层就足够好,而最近的深度学习观点认为在一定范围内,层数越多,模型的描述和还原能力越强。
偏置结点是为了描述训练数据中没有的特征,偏置结点对于下一层的每一个结点的权重的不同而生产不同的偏置,于是可以认为偏置是每一个结点(除输入层外)的属性。
训练一个BP神经网络,实际上就是在外界输入样本的刺激下不断调整网络的权重和偏置这两个参数,以使网络的输出不断接近期望的输出,BP神经网络的训练过程分两部分:
- 前向传输,逐层波浪式的传递输出值;
- 逆向反馈,反向逐层调整权重和偏置;
2.
BP神经网络训练
这部分应当说是整个BP神经网络形成的引擎,驱动着样本训练过程的执行。由BP神经网络的基本模型知道,反馈学习机制包括两大部分,一是BP神经网络产生预测的结果,二是通过预测的结果和样本的准确结果进行比对,然后对神经元进行误差量的修正。因此,我们用两个函数来表示这样的两个过程,训练过程中还对平均误差 e 进行监控,如果达到了设定的精度即可完成训练。由于不一定能够到达预期设定的精度要求,我们添加一个训练次数的参数,如果次数达到也退出训练。
初始化BP神经网络
初始化主要是涉及两个方面的功能,一方面是对读取的训练样本数据进行归一化处理,归一化处理就是指的就是将数据转换成0~1之间。在BP神经网络理论里面,并没有对这个进行要求,不过实际实践过程中,归一化处理是不可或缺的。因为理论模型没考虑到,BP神经网络收敛的速率问题,一般来说神经元的输出对于0~1之间的数据非常敏感,归一化能够显著提高训练效率。可以用以下公式来对其进行归一化,其中 加个常数A 是为了防止出现 0 的情况(0不能为分母)。
y=(x-MinValue+A)/(MaxValue-MinValue+A)
另一方面,就是对神经元的权重进行初始化了,数据归一到了(0~1)之间,那么权重初始化为(-1~1)之间的数据,另外对修正量赋值为0。实现参考代码如下:
一些数据的定义
首先,我们介绍些下文中描述的程序里面的一些重要数据的定义。
#define Data 820#define In 2#define Out 1#define Neuron 45#define TrainC 5500
Data 用来表示已经知道的数据样本的数量,也就是训练样本的数量。In 表示对于每个样本有多少个输入变量; Out 表示对于每个样本有多少个输出变量。Neuron 表示神经元的数量,TrainC 来表示训练的次数。再来我们看对神经网络描述的数据定义,来看下面这张图里面的数据类型都是 double 型。
参考:
1.转文:
转载自:
最近在看深度学习的东西,一开始看的吴恩达的UFLDL教程,有中文版就直接看了,后来发现有些地方总是不是很明确,又去看英文版,然后又找了些资料看,才发现,中文版的译者在翻译的时候会对省略的公式推导过程进行补充,但是补充的又是错的,难怪觉得有问题。反向传播法其实是神经网络的基础了,但是很多人在学的时候总是会遇到一些问题,或者看到大篇的公式觉得好像很难就退缩了,其实不难,就是一个链式求导法则反复用。如果不想看公式,可以直接把数值带进去,实际的计算一下,体会一下这个过程之后再来推导公式,这样就会觉得很容易了。
说到神经网络,大家看到这个图应该不陌生:
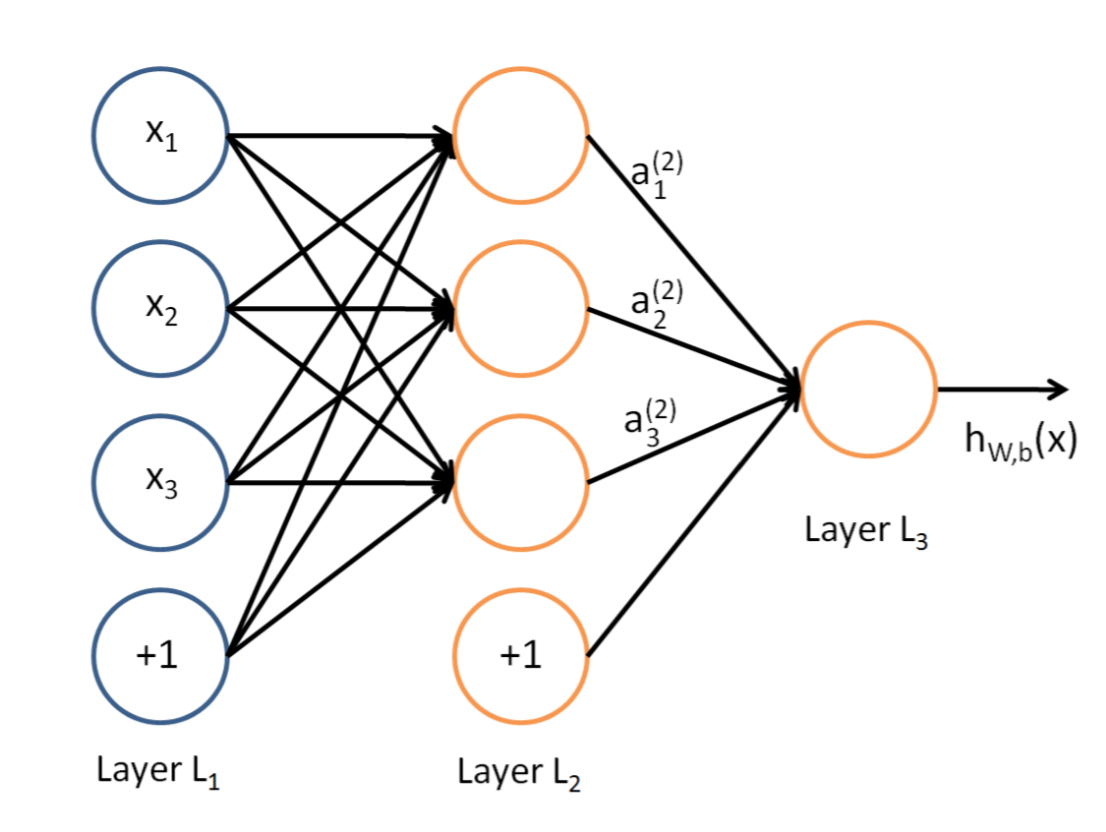
这是典型的三层神经网络的基本构成,Layer L1是输入层,Layer L2是隐含层,Layer L3是隐含层,我们现在手里有一堆数据{x1,x2,x3,...,xn},输出也是一堆数据{y1,y2,y3,...,yn},现在要他们在隐含层做某种变换,让你把数据灌进去后得到你期望的输出。如果你希望你的输出和原始输入一样,那么就是最常见的自编码模型(Auto-Encoder)。可能有人会问,为什么要输入输出都一样呢?有什么用啊?其实应用挺广的,在图像识别,文本分类等等都会用到,我会专门再写一篇Auto-Encoder的文章来说明,包括一些变种之类的。如果你的输出和原始输入不一样,那么就是很常见的人工神经网络了,相当于让原始数据通过一个映射来得到我们想要的输出数据,也就是我们今天要讲的话题。
本文直接举一个例子,带入数值演示反向传播法的过程,公式的推导等到下次写Auto-Encoder的时候再写,其实也很简单,感兴趣的同学可以自己推导下试试:)(注:本文假设你已经懂得基本的神经网络构成,如果完全不懂,可以参考Poll写的笔记:)
假设,你有这样一个网络层:

第一层是输入层,包含两个神经元i1,i2,和截距项b1;第二层是隐含层,包含两个神经元h1,h2和截距项b2,第三层是输出o1,o2,每条线上标的wi是层与层之间连接的权重,激活函数我们默认为sigmoid函数。
现在对他们赋上初值,如下图:
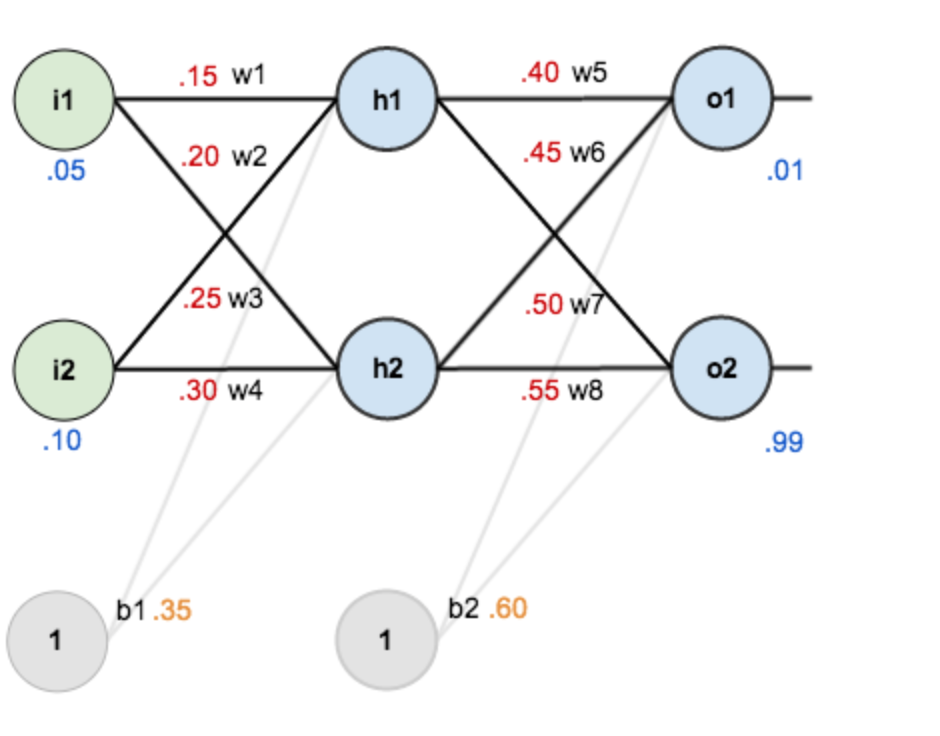
其中,输入数据 i1=0.05,i2=0.10;
输出数据 o1=0.01,o2=0.99;
初始权重 w1=0.15,w2=0.20,w3=0.25,w4=0.30;
w5=0.40,w6=0.45,w7=0.50,w8=0.55
目标:给出输入数据i1,i2(0.05和0.10),使输出尽可能与原始输出o1,o2(0.01和0.99)接近。
Step 1 前向传播
1.输入层---->隐含层:
计算神经元h1的输入加权和:

神经元h1的输出o1:(此处用到激活函数为sigmoid函数):
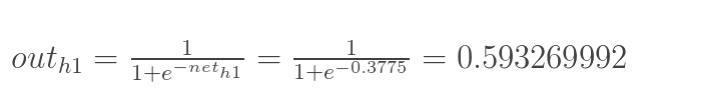
同理,可计算出神经元h2的输出o2:
![]()
2.隐含层---->输出层:
计算输出层神经元o1和o2的值:

![]()
这样前向传播的过程就结束了,我们得到输出值为[0.75136079 , 0.772928465],与实际值[0.01 , 0.99]相差还很远,现在我们对误差进行反向传播,更新权值,重新计算输出。
Step 2 反向传播
1.计算总误差
总误差:(square error)
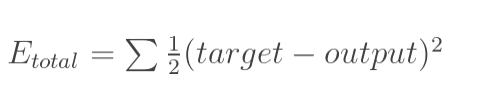
但是有两个输出,所以分别计算o1和o2的误差,总误差为两者之和:


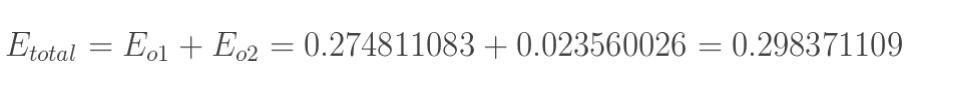
2.隐含层---->输出层的权值更新:
以权重参数w5为例,如果我们想知道w5对整体误差产生了多少影响,可以用整体误差对w5求偏导求出:(链式法则)

下面的图可以更直观的看清楚误差是怎样反向传播的:

现在我们来分别计算每个式子的值:
计算![]() :
:

计算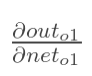 :
:

(这一步实际上就是对sigmoid函数求导,比较简单,可以自己推导一下)
计算 :
:
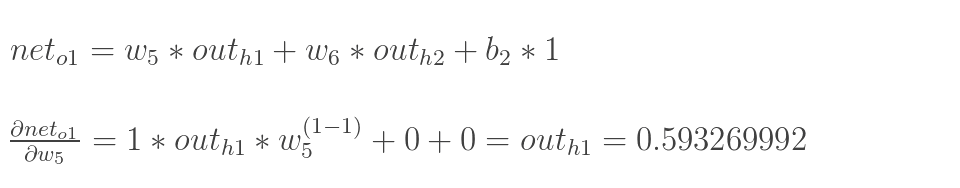
最后三者相乘:

这样我们就计算出整体误差E(total)对w5的偏导值。
回过头来再看看上面的公式,我们发现:

为了表达方便,用![]() 来表示输出层的误差:
来表示输出层的误差:

因此,整体误差E(total)对w5的偏导公式可以写成:

如果输出层误差计为负的话,也可以写成:

最后我们来更新w5的值:
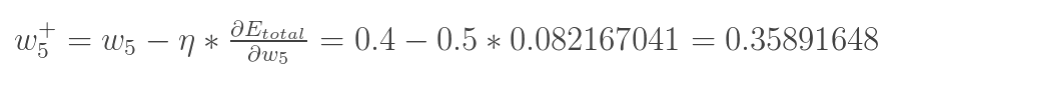
(其中,![]() 是学习速率,这里我们取0.5)
是学习速率,这里我们取0.5)
同理,可更新w6,w7,w8:

3.隐含层---->隐含层的权值更新:
方法其实与上面说的差不多,但是有个地方需要变一下,在上文计算总误差对w5的偏导时,是从out(o1)---->net(o1)---->w5,但是在隐含层之间的权值更新时,是out(h1)---->net(h1)---->w1,而out(h1)会接受E(o1)和E(o2)两个地方传来的误差,所以这个地方两个都要计算。
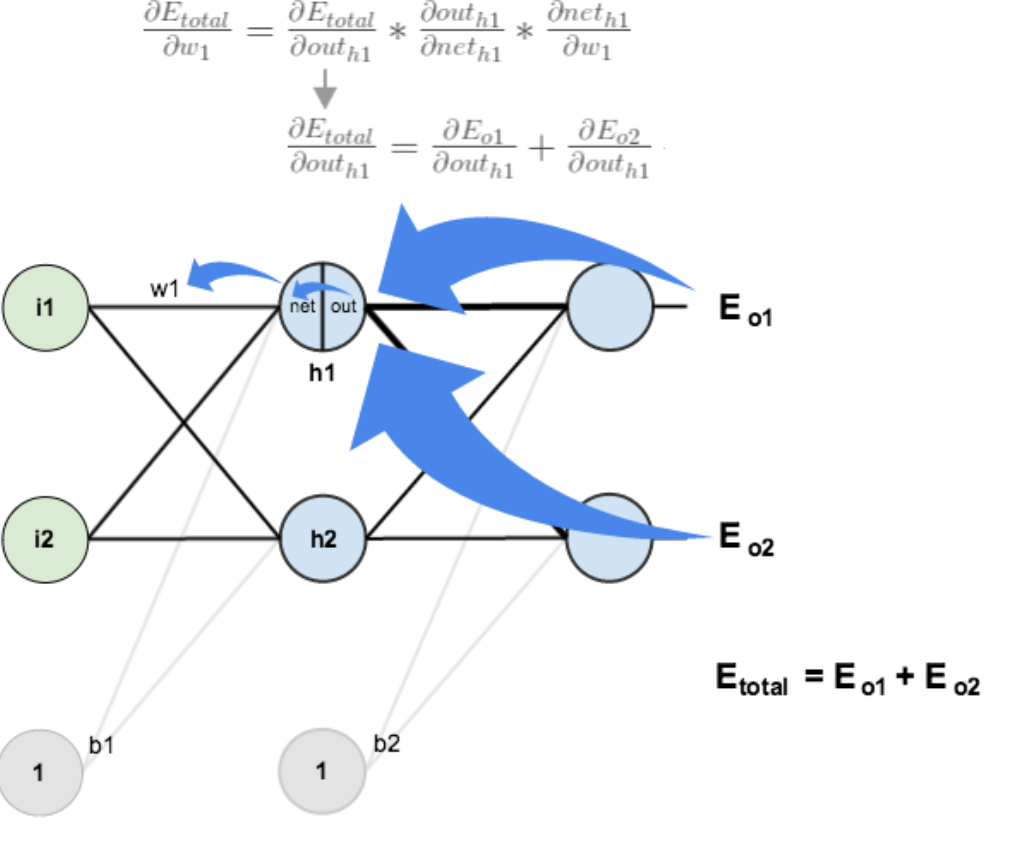
计算![]() :
:

先计算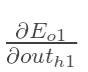 :
:
![]()
![]()
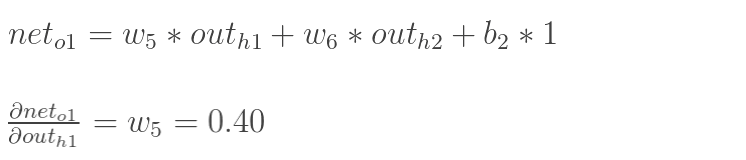
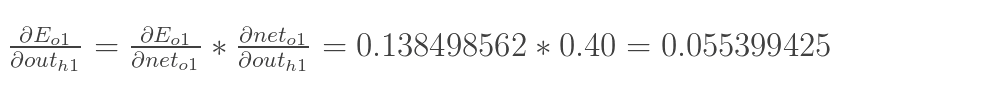
同理,计算出:
![]()
两者相加得到总值:
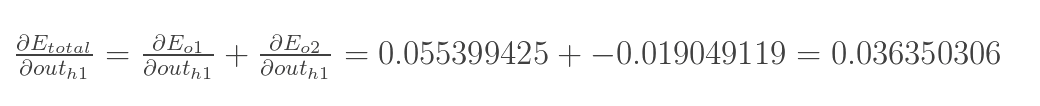
再计算![]() :
:

再计算![]() :
:

最后,三者相乘:

为了简化公式,用sigma(h1)表示隐含层单元h1的误差:

最后,更新w1的权值:
![]()
同理,额可更新w2,w3,w4的权值:

这样误差反向传播法就完成了,最后我们再把更新的权值重新计算,不停地迭代,在这个例子中第一次迭代之后,总误差E(total)由0.298371109下降至0.291027924。迭代10000次后,总误差为0.000035085,输出为[0.015912196,0.984065734](原输入为[0.01,0.99]),证明效果还是不错的。